Mastering AI Model Validation - A Comprehensive Guide for Success
AI is everywhere these days! Yet is has existed since the beginning of the computer age. What is so different from 25 years ago? What makes it more powerful, more present? Why all the fuss? Over the last 10 years machine learning has become extremely powerful.
Rather than programmers giving machine learning AIs a definitive list of instructions on how to complete a task, the AIs have to learn how to do the task themselves. There are many ways to attempt this, but the most popular approach involves software that is trained by example.
The importance of validating AI models
AI is already involved in making important processes (like translations and summarizations) and yet AI is often biased, meaning its recommendations can be too. Time after time, researchers have found that neural networks pick up biases from the data sets they are trained on. For example, face recognition algorithms have much lower accuracy for anyone who is not a white man.
AI decisions are also opaque or referred to as a “Black box”. How neural networks come to conclusions is very hard to analyze, meaning if they make a crucial mistake, such as missing cancer in an image, it’s very difficult to find out why they made the mistake or to hold them accountable.
Validating AI models ensures accuracy, robustness, and reliability.
Often creating and validating these sets in a time and resource consuming activity which does not always help the business case due to its labor-intensive nature. But validating AI models is necessary and ensures accuracy, robustness, and reliability.
Data Splitting for Model Validation
The primary reason for data splitting is to avoid overfitting , which occurs when the model is too complex and fits the training data too well, resulting in poor generalization performance on new data. By splitting the data, we can ensure that the model is not overfitting to the training data and is generalizing well to new data.
Data splitting also provides an unbiased estimate of the model’s performance. If we use the same data for training and testing, the model will perform well on the training data but may not generalize well to new data. By using a separate testing set, we can obtain an unbiased estimate of the model’s performance on new data.
Determining Validation Set Size
To calculate the size of the validation set, there is no one-size-fits-all answer. However, a common approach is to use a 70/30 or 80/20 split for the training and validation sets, respectively. The size of the validation set should be large enough to provide a representative sample of the data but small enough to avoid overfitting. A good rule of thumb is to use at least 5% of the total data for the validation set. That means that for a population of 40000 you need a sample set of 2000.
This online calculator helps to calculate sample sizes - Sample Size Calculator - for test and validation purposes. It provides insights into how the right validation set size contributes to an effective model assessment.
Methods of Model Validation: Cross Validation Cross-validation is a technique used in machine learning to evaluate the performance of a model. It involves dividing the dataset into smaller groups and then averaging the performance in each group to reduce the impact of partition randomness on the results. Nevertheless, each method has its own bias toward more positive or negative results. Here are some of the most commonly used cross-validation techniques:
-
Train-Test Split Method: This method randomly partitions the dataset into two subsets (called training and test sets) so that the predefined percentage of the entire dataset is in the training set. Then, we train our machine learning model on the training set and evaluate its performance on the test set. In this way, we are always sure that the samples used for training are not used for evaluation and vice versa.
-
K-Fold Cross-Validation: In k-fold cross-validation, we first divide our dataset into k equally sized subsets. Then, we repeat the train-test method k times such that each time one of the k subsets is used as a test set and the rest k-1 subsets are used together as a training set. Finally, we compute the estimate of the model’s performance estimate by averaging the scores over the k trials.
-
Leave-One-Out Cross-Validation: In leave-one-out cross-validation, we use all but one sample for training and the remaining sample for testing. We repeat this process for all samples in the dataset and average the performance over all trials.
A Power Platform Example
Let us say we have created a model in AI builder, and you want to see if it works as expected. Power Platform comes some standard prediction engines and features, still it is always a good idea to validate the outcome of a process.
This technique can also be used with models created by other technologies as well.
An easy way to do this in Power platform is with a Power Automate flow.
- Put your validation files in one folder. (you can even create them using a generation flow)
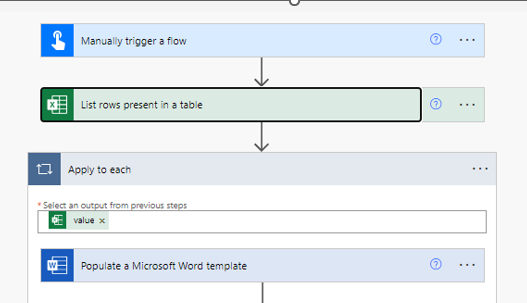
-
Create a database with all the (meta)data you expect the model to find in the files.
-
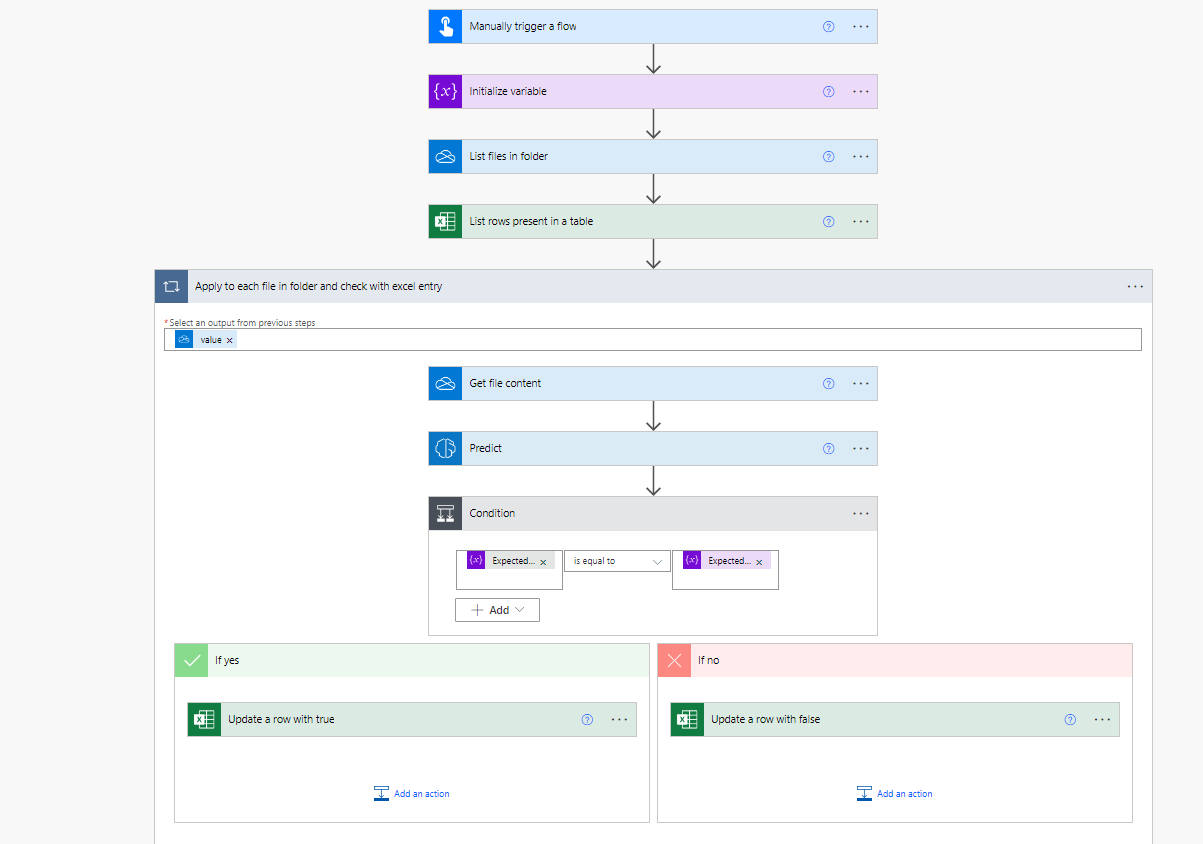
Create a flow that reads the files, runs the model and verifies the data found against the data source.
-
Put the results in a file or dashboard.
It can look something like this:
Key Takeaways
Data splitting is essential for avoiding overfitting and obtaining an unbiased estimate of the model’s performance. It is a crucial step in the validation process. The choice of cross-validation technique depends on the size of the dataset, the number of features, and the computational resources available.
These techniques are used to evaluate the performance of a machine learning model and to reduce the impact of partition randomness on the results. It helps ensure the overall accuracy, robustness, and reliability of the business process.
Check out Machine Learning Mastery where you’ll find “not so dry” material on this topic.
My focus is on structuring, automating and managing business processes using Agile and DevOps best practices. This creates working environments where business continuity, transparency and human capital come first. Reach out to me on LinkedIn or check out my github or blog for more tips and tricks.
The ideas and underlying essence are original and generated by a human author. The organization, grammar, and presentation may have been enhanced by the use of AI.